You are currently browsing the tag archive for the ‘indo-european’ tag.
Индоевропейские языки: не из Ирана, а из степи
В течение многих лет ученые спорили о происхождении индоевропейских языков в Южной Азии. Некоторые теории указывали на происхождение из района иранского плато, но новые данные свидетельствуют о другом. Исследование под названием «Формирование человеческих популяций в Южной и Центральной Азии» предоставляет отрицательные доказательства против теории иранского плато и вместо этого поддерживает идею о том, что эти языки распространились из степного региона. Я изучал необычайное родство между индоиранскими языками, особенно между ведическим санскритом и славянскими языками. Родство это очевидно, если вы посмотрите на краткий список глаголов и существительных в моих предыдущих блогах. Это лишь малая часть родственных слов, вошедших в готовящийся к изданию Русско-Санскритский Сравнительный словарь. В статье дается некоторое объяснение этой неоспоримой близости.
Некоторые исследователи полагают, что Бактрийско-Маргианский археологический комплекс (БМАК) (Bactria-Margiana Archaeological Complex), древняя цивилизация в Центральной Азии, которая имела место в Центральной Азии, возможно, была источником индоевропейских языков на Индийском субконтиненте, поскольку BMAC находился недалеко от Южной Азии, а между BMAC и людьми цивилизации долины Инда существовали связи. Вопреки предыдущим теориям, новые генетические данные показывают, что основная группа людей региона BMAC не имела какой-либо заметной генетической связи со степными скотоводами и что они не сыграли большой роли в происхождении более поздних жителей Южной Азии. Однако у некоторых людей в регионе BMAC появились гены степных скотоводов примерно в 2000 году до нашей эры, когда они также начали появляться в южном степном регионе.
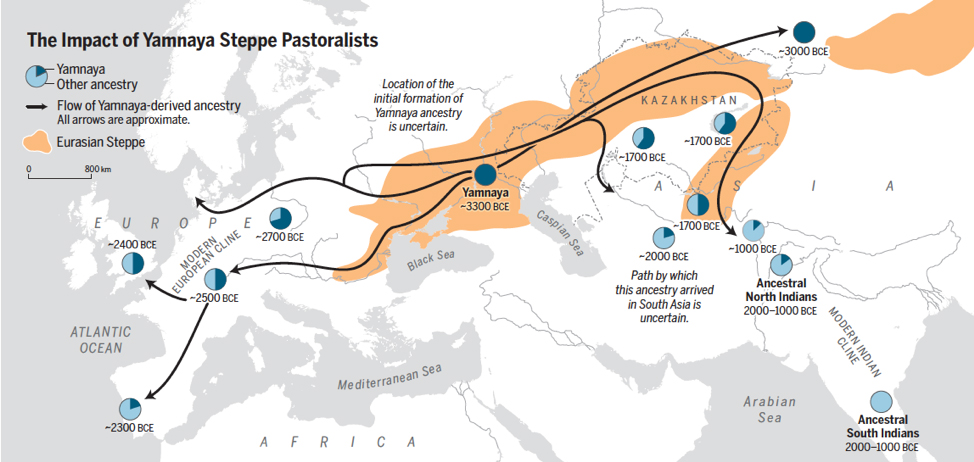
Крупнейшее в истории исследование древней ДНК освещает тысячелетнюю историю населения Центральной и Южной Азии. (Источник изображения: The Formation of Human Populations in South and Central Asia)
В новом исследовании были изучены данные древних людей из долины Сват в самой северной части Южной Азии, и исследователи обнаружили, что эти степные гены переместились дальше на юг в первой половине 2-го тысячелетия до нашей эры. На их долю приходится до 30% генов современных групп Южной Азии.
Гены степей Южной Азии аналогичны генам Восточной Европы бронзового века. Это говорит о том, что существовала группа людей, которые перемещались между этими регионами, и это движение, возможно, сыграло роль в формировании сходства между индоиранскими и славянскими языками.
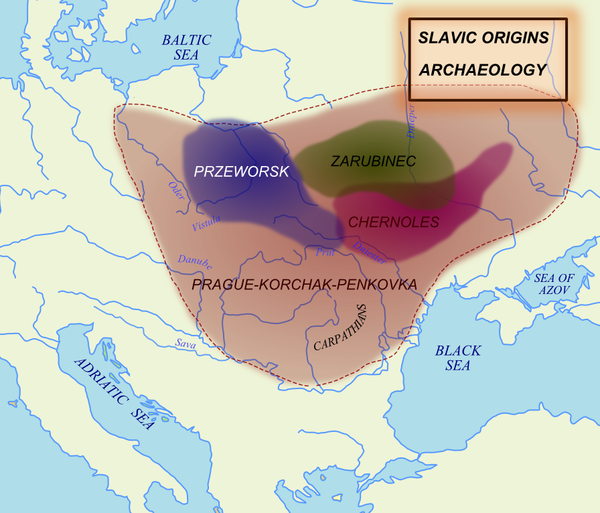
Раннеславянские артефакты чаще всего связаны с зарубинецкой, пшеворской и черняховской культурами, охватывающими западную часть Степи. Примерно в этих же районах предполагается и прародина славян. Праславянский диалект, видимо, обособился и сформировался в Потисье (водосборный бассейн реки Тиса) и Закарпатье.
Это приблизительная адаптация более ранних карт, показывающих расположение ранних славян (зеленый) и BMAC (фиолетовый).
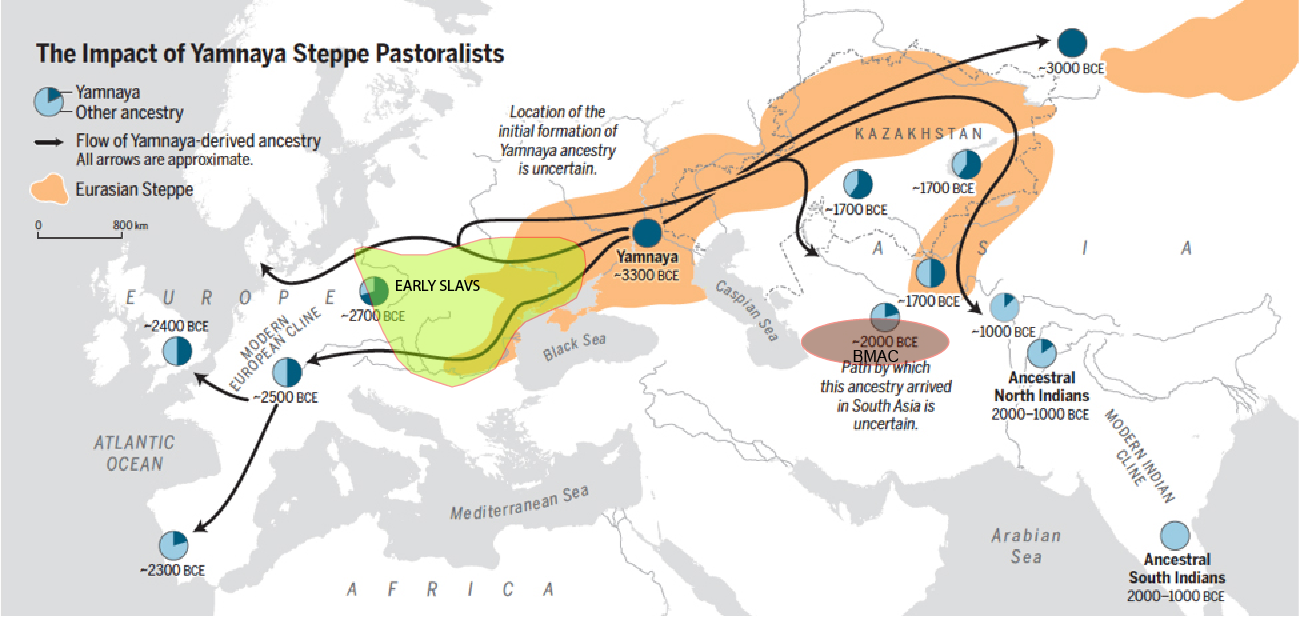
Исследователи проанализировали древнюю ДНК и обнаружили, что их предки из Центральной Степи проникли в Южную Азию в первой половине 2-го тысячелетия до нашей эры. Это генетическое свидетельство может подтвердить связь между степными и индоевропейскими языками Южной Азии.
Материальные культурные различия и генетические связи
Что еще более интригует, так это различия в материальной культуре между Степью и Южной Азией в эпоху бронзы, но несмотря на значительные отличия в артефактах и технологиях, генетические данные свидетельствуют о распространении генов, связанных со Степью, в Южную Азию. Это явление чем-то похоже на ситуацию с культурой «колоколовидных кубков» в Европе, где люди степного происхождения оказали значительное демографическое влияние, но переняли местную материальную культуру.
Однако есть еще одна интересная подсказка: у людей, ответственных за сохранение древних санскритских текстов, таких как брамины, больше генов из степного региона, чем можно было бы ожидать, основываясь на простой смеси различных южноазиатских генов. Это еще одно свидетельство того, что индоевропейские языки в Южной Азии могли прийти из Степного региона до 2000 года до нашей эры.
Indo-European Languages: Not from Iran, But the Steppe
For years, scholars have debated the origins of Indo-European languages in South Asia. Some theories pointed to an Iranian plateau origin, but new evidence suggests a different story. The study titled The Formation of Human Populations in South and Central Asia provides negative evidence against the Iranian plateau theory and instead supports the idea that these languages spread from the Steppe region. I have been studying the extraordinary affinity between Indo-Iranian, especially between Vedic Sanskrit and Slavic languages which is obvious if you look at the short list of verbs and nouns in my earlier blogs. This is just a fraction of the cognate words included in the Russian- Sanskrit Comparative Dictionary being prepared for publication. The article gives some explanation for this undeniable affinity.
Some researchers think that the Bactria-Margiana Archaeological Complex (BMAC) (Bactria-Margiana Archaeological Complex), an ancient civilization in Central Asia, which was a place in Central Asia, might have been where Indo-European languages began in the Indian subcontinent. They believe this because the BMAC was close to South Asia, and there were connections between the BMAC and the people of the Indus Valley Civilization. Contrary to the previous theories, the new genetic evidence shows that the main group of people of BMAC region didn’t have any notable genetic connection to Steppe pastoralists and that they didn’t play a big part in the ancestry of later South Asians. However, some individuals in the BMAC region started having Steppe pastoralist genes around the year 2000 BCE, which is when it also began appearing in the southern Steppe region.
The largest-ever ancient DNA study illuminates millennia of Central and South Asian population history. (Image source: The Formation of Human Populations in South and Central Asia)
The new study looked at data from ancient people in the Swat Valley in the northernmost part of South Asia, and the researchers found that these Steppe genes moved further south in the first half of the 2nd millennium BCE. They contributed up to 30% of the genes of modern South Asian groups.
The Steppe genes in South Asia are similar to the ones in Bronze Age Eastern Europe. This suggests that there was a group of people who moved between these regions, and this movement may have played a role in shaping the similarities between Indo-Iranian and Slavic languages.
Early Slavic artefacts are most often linked to the Zarubintsy, Przeworsk and Chernyakhov cultures embrace the Western part of the Steppe.
This is a rough adaptation of the earlier maps showing the locations of Early Slaves (green) and BMAC (purple).
The researchers analysed ancient DNA and found that Central Steppe ancestry made its way into South Asia during the first half of the 2nd millennium BCE. This genetic evidence strengthens the connection between the Steppe and Indo-European languages in South Asia. It’s a bit like fitting pieces of a puzzle together, as genetic data supports the idea of language migration from one region to another.
Material Culture Differences and Genetic Links
What’s even more intriguing is the disparity in material culture between the Steppe and South Asia during the Bronze Age. Despite significant differences in artefacts and technologies, genetic evidence suggests the spread of Steppe-related genes into South Asia. This phenomenon is somewhat akin to the Beaker Complex in Europe, where people with Steppe ancestry made significant demographic impacts while adopting local material culture.
However, there’s another interesting clue: the people who have been responsible for preserving ancient Sanskrit texts, like Brahmins, have more genes from the Steppe region than what we would expect based on a simple mix of different South Asian genes. This is another piece of evidence that suggests that the Indo-European languages in South Asia might have come from the Steppe region before the year 2000 BCE.
I have not published any new posts for several years but the work on the comparative dictionary was continuing. Regrettably, my co-author and teacher Alexander Shaposhikov died last year. However, he has finished most of his part of work and also left many comments that allow me to continue with this project and lead it to the end. Currently, the dictionary is 90 per cent complete. It contains approximately 870 completed entries out of a total of 1000 planned. I hope to publish the dictionary by September 2023.
The dictionary is the first comprehensive study of lexical similarities between Russian and Sanskrit. In creating it, the authors drew on the contributions and historical works of Russian and other linguistic researchers of etymology, especially the Russian Academician O. N. Trubachev and “Etymological Dictionary of Slavic Languages” published by Vinogradov Instutute of Russian Language. This is a demonstration draft with only a small number (90) of entries including words starting with (russian) B (rating 5-3). Progress since the previous draft:
The introductory part has been thoroughly edited and page typesetting largely completed (hyphenation, “hanging” prepositions, spacing etc.).
Dictionary entries have been edited, style and spelling corrected. Proper typesetting of dictionary entries is still to be done. Biblio references were checked, sorted and standardised to GOST. Cover draft was slightly edited.
Please note that in the online text the Devanagari ligatures are not always reproduced correctly and some words seem stuck together, so we recommend to download a .pdf file which is fairly small in size.
________________________
Cловарь является первым систематическим сводом лексических схождений русского и санскрита. При его создании авторы опирались на достижения исторического языкознания, работы по этимологии российских и зарубежных исследователей и особенно на наследие академика О. Н. Трубачёва и «Этимологический словарь славянских языков. Это демонстрационный черновик с небольшим количеством (90) слов, начинающихся с (рус.) B (рейтинг 5-3).
Прогресс по сравнению с предыдущим черновиком:
Вступительная часть тщательно отредактирована, в основном завершена верстка страниц (расстановка переносов, «висячие» предлоги, интервалы и т. д.).
Словарные статьи отредактированы, исправлены стиль и орфография. Надлежащая верстка словарных статей еще предстоит. Библиографические ссылки были проверены, отсортированы и приведены в соответствие с ГОСТ. Проект обложки был немного отредактирован.
Обратите внимание, что в онлайн-тексте лигатуры деванагари не всегда воспроизводятся правильно, а некоторые слова кажутся слипшимися, поэтому мы рекомендуем вам скачать файл .pdf, который имеет довольно небольшой размер.
Мы приветствуем любую конструктивную критику и комментарии.
I have decided to upload a draft of my RUSSIAN – SANSKRIT DICTIONARY OF COMMON AND COGNATE WORDS which is the result of some eight years of work. This dictionary has been conceived as a practical reference book with the objective of providing factual material for researchers in the field of the Indo-European linguistics or anyone interested in etymology, semantics and the origin of the Indo-European, particularly, Slavonic languages. Compiling a dictionary is time-consuming and it is a mammoth task to do for a single person. The first draft published here is only a rough approximation. It contains only 488 entries, which is about a quarter of the planned volume, and still lacks some essential parts in the Introduction section. The entries have not yet been properly proof-read and I am constantly updating the comments.
You may access the text at my page on Academia.edu

Although this work is titled ‘Dictionary’ it is neither a traditional Russian-Sanskrit dictionary nor a formal etymological dictionary, but rather a catalogue of various cognate, common or otherwise connected Russian and Sanskrit words, arranged is a systematic way with cross-references, explanatory notes, links to other Slavonic and Indo-European languages, indexes and other features aimed at making it a valuable and convenient reference book. The specific task called for employing both Cyrillic and Devanagarī scripts throughout the book because transliteration, however elaborate, cannot fully replace the native writing system. Since it is unlikely that every reader would be proficient in both scripts, each word is accompanied by a conventional transliteration.
In writing this book I endeavoured to go through all major works dedicated to this issue starting from the discovery of Sanskrit and its relation to the European languages in general, and particularly to Slavonic, covering the period from the 17th century up to the modern days. Each proposed cognate word has been carefully evaluated, checked through various dictionaries and, sometimes, re-linked or rejected. This method provided some eight hundred pairs that made the back-bone of the dictionary. The rest of the cognate pairs (about another thousand two hundred) are the result of many years of scrupulous research.
Many cognate pairs are obvious, some need more or less detailed explanations and might be difficult to apprehend without some basic knowledge of the principal linguistic concepts and terms. This is why the dictionary is prefaced by an Introduction containing some essential information about the Russian and Sanskrit languages and their phonetic and grammatical features with particular attention to the principal rules of sound correlation. This section is now in work and it is not included in this draft.
I would be grateful for any constructive criticism or comments. If you would like to support this project there are several ways of helping me with the work:
- report any spelling or other mistakes that you have noticed
- suggest any other cognate pairs
- check the various cognates I mention in Slavonic and other languages if they happen to be in your native language
I would like to demonstrate here the remarkable phonetic affinity between Sanskrit and Russian taking two dozen of unquestionable cognate pairs as examples. It is well known that all Indo-European languages contain a greater or lesser number of common words but only Slavonic and, to a lesser degree, Baltic languages approximate Sanskrit to such an extent that in me instances the difference between certain Slavonic languages could be greater than between some Slavonic languages and Sanskrit.
Take the word for `spindle’: Sanskrit vartana, Russian vereteno, Bulgarian. vretе́no, Slovenian vreténo, Czech vřeteno, Polish wrzeciono, Upper Sorbian wrjećeno and Lower Sorbian rjeśeno. The phonetic shape of cognates in other Indo-European languages differs considerably.
A good example is the word `alive’: Sanskrit jīva, Russian živ, Lithuanian gývas, Greek bíos, Latin vīvus, Irish biu, Gothic qius, Old High German quес, and English quick.
Transliteration notes
Sanskrit: ā, ī, ū – long sounds; ṛ = ri (a short i similar to Rus. soft рь/r‘); c=ch; j similar to j in “jam”; ṣ similar to sh; ś a subtler sort of sh, closer to German /ch/ as in ich.
Russian: š similar to sh; č = ch; ž = like g in garage , the vowel y is a sort of ‘hard’ i sounding somewhat similar to unstressed i in Eng. it . the sign ‘ indicates softness and stands for a very short i . Vowels with j are iotated so ju would be similar to Eng. you and Skr. yu etc.
| Skt. | Rus. | Lith. | Greek | Latin | Goth. | OHG/Ger. | Eng |
| bhrātṛ | brat | brólis | phrátēr | frāter | brōþar | Bruder | brother |
| bhrū | brov’ | bruvis | ophrus | brāwa | brow | ||
| vidhava | vdova | vidua | widuwō | Widuwō | widow | ||
| vartana | veretenò | Wirtel | spindle | ||||
| viś | ves’ | viešė | oikos | vīcus | weihs | abode, village, home | |
| vātṛ | veter | vėtra | wind | ||||
| vṛka | volk | vilkas | lýkos | lupus | wulfs | Wulfs | wolf |
| dvār | dver’ | dùrys | thýra | forēs | daúr | turi | door |
| dvaya | dvoe | dvejì | twaddjē | two of smb. | |||
| devṛ | dever’ | dieveris | daḗr | lēvir | zeihhur | husband’s brother | |
| dina | den’ | dienà | diēs | day | |||
| dam, dama | dom | nãmas(?) | dō̂ma | domus | house, home | ||
| janī | žena | gynḗ | qino | wife | |||
| jīva | živ | gývas | bíos | vīvus | qius | quес | alive |
| jñāna | znanie | žinios | gnōsis | knowledge | |||
| kada | kogda | kada | when | ||||
| katara | kotoryj | kuris | póteros | uter | ƕаþаr | hwedar | which |
| kumbha | kub | kýmbos | cupa | pitcher | |||
| laghu | ljogok | leñgvas | elaphrós | levis | leihts | lungar | light |
| roci | luč | leukós | lūх | liuhaþ | light, ray | ||
| madhu | mjod | medùs | méthy | metu | honey | ||
| mūṣ | myš’ | mŷs | mūs | mûs | mouse | ||
| mās | mjaso | mėsà | mimz(?) | meat |
Note that we compare the attested languages and not hypothetical `reconstructions’ however, according to Antoine Meillet:
“[..] Baltic and Slavic show the common trait of never having undergone in the course of their development any sudden systemic upheaval. […] there is no indication of a serious dislocation of any part of the linguistic system at any time. The sound structure has in general remained intact to the present. […] Baltic and Slavic are consequently the only languages in which certain modern word-forms resemble those reconstructed for Common Indo-European.” ( The Indo-European Dialects [Eng. translation of Les dialectes indo-européens (1908)], University of Alabama Press, 1967, pp. 59-60).
See also my other posts:
https://borissoff.wordpress.com/2012/11/18/russian-sanskrit-verbs-3/
https://borissoff.wordpress.com/2012/12/13/russian-sanskrit-nouns/
I would like to recommend this popular article “Making Archaeology Speak – Archaeology and Linguistics” by Maciej Mateusz Wencel (born in Gdynia, northern Poland, currently reads an Undergraduate Course in Archaeology and Anthropology at Oxford University). It is very well written and well balanced. I have arrived to very similar ideas and agree with most of what he has written.
Here are some extracts: Read the rest of this entry »
In my previous post I gave a list of some Sanskrit-Russian cognate verbs which showed a remarkable phono-semantic affinity. This closeness also extends to grammatical endings. I would like to demonstrate it here taking as an example one Sanskrit verb jīvati ‘lives, is or remains alive’. For Russian I chose a less used form живать živat‘ which in modern Russian is predominantly used with prefixes e. g. про–живать pro–živat‘. It is an exact analogue of Sankrit jīvati and Avestan ǰvaiti. To make the comparison more obvious I also included Lithuanian and Latin cognates. Hopefully, this comparison is self-explanatory.
Some notes:
There are many theories on the nature of verbal systems in the ancient dialects that are commonly referred to as ‘Indo-European’ and ‘proto-Indo-European’. As I have already written in the comments, I do not accept the idea of a uniform ‘proto-language’. I do use these terms but only as ‘umbrella terms’ meaning a certain simplified generalisation.
There is a general consensus that ‘Indo-European’ verbs were conjugated (at least in the present tense) by person (First, Second and Third) and by number (Singular, Dual and Plural). These grammatical categories were expressed by means of special endings which were added to the verbal stem . It should be noted that ‘verbal stem’ as well as ‘verbal root’ are abstractions. For example, ancient Sanskrit grammarians did not single out the root. Instead they operated with dhātu ‘constituent part, ingredient, element’. The notion of a verbal root was brought in by Western scholars inspired by Semitic monosyllabic CVC (consonant-vowel-consonant) roots. So when we see in a modern dictionary a root jīv, according to Pāṇini, this would be a dhātu jīva ‘living, existing, alive’. From the point of Western linguists it would be viewed as a CVC root jīv + a so-called ‘thematic vowel‘ –a. Together they would form a ‘stem’ which may be taken as an equivalent of dhātu. For convenience I mark the root in italic, thematic vowel in blue and the personal ending in red. I also added hypothetical (reconstructed) thematic vowels and personal endings based on a more traditional interpretation of Fortson (Indo-European Language and Culture. Blackwell Publishing. 2004).
Transliteration:
Sanskrit j is [ɟ͡ʝ] (similar to j in jam], ḥ is a visarga ‘sending forth, letting go, liberation, emission, discharge’. It is a voiceless ‘breath out’ like an energetic [h]. In certain positions at words conjunctions visarga becomes /s/ or /r/. Long vowels are marked with a bar above so ī is [i:]. Because Russian stressed vowels are primarily characterised by length, I transliterate them in the similar manner so ā is a stressed a . By the way, Sanskrit a अ should be pronounced as [ɐ] or [ə] which exactly corresponds to the Russian unstressed a.
I transliterate here Cyrillic using the same system of Latin transliteration as commonly used for Devanāgarī so Russian ш [ʂ] commonly transliterated as š or sh, appears here as ṣ. This is particularly justified because Sanskrit ṣ is also a retroflex sibilant. Also I transliterate here ж [ʒ] (ž or zh) as j. However, Lithuanian j is [j]. Lithuanian g is [g] and y is [iː].
| Singular | Hypothetical “IE” | Plural | Hypothetical “IE” | |||
| 1st (I) | Skr. | jīvāmi |
*-oh₂ | 1st (we) | jīvāmaḥ | *-omos |
| Rus. | jivāyu | jivāem | ||||
| Lith. | gyvoju |
gyvuojame | ||||
| Lat. | vīvō | vīvimus | ||||
| 2nd (you) | Skr. | jīvasi | *-esi | 2nd (you) | jīvatha | *-ete |
| Rus. | jivāeṣ | jivāete | ||||
| Lith. | gyvuoji | gyvuojate | ||||
| Lat | vīvis | vīvitis | ||||
| 3rd (he/she/it) | Skr. | jīvati | *-eti | 3rd (they) | jīvanti | *-onti |
| Rus. | jivāet | jivāyut | ||||
| Lith. | gyvuoja | gyvuoja | ||||
| Lat. | vīvit | vīvunt |

I recommend this new book as a fairly balanced introduction into the argument on the origins of Sanskrit and the Vedic culture.
“The earliest Indian inscriptions date from the third century before Christ. Archaeological and palaeo-anthropological evidence, as well as the Indian oral tradition, consistently point to the ‘continuity’ of the Indian Civilization back to a much earlier date. However, the question of the origin of Indian Civilization prior to that period remains open. There are three main schools of thought in this regard. Proponents of the Indo-European theory suggest that the Sanskrit language and civilization were an intrusion into India from the West. Proponents of the continuity theory, on the contrary, believe that they arose locally. The third school of thought proposes that the current scholarship is insufficient to trace the Sanskrit language and civilization back to pre-historical times, and that further research is required to develop a fair comparison between the European languages and the Indian languages. Published literature in the field often reflects one or the other of these perspectives, rather than offering an integrated view. Read the rest of this entry »
The topic of Iranian loans into Slavonic has become a common place in Slavistics reflecting, to a considerable extent, the stereotype view on Slavonic mainly as a target language for borrowing. In reality, the number of truly attested Iranian loans is confined to a rather short list of words. Strictly speaking, the term ‘iranism (иранизм)’, widely used in Russian linguistic literature, stands for a direct borrowing from one of the attested Iranian languages. However, according to the academician of the Russian Academy of Sciences Oleg Nikolajevič Trubačev, such loans are limited to a few cultural terms such as *kotъ ‘stall, small cattle shed’, *čьrtogъ ‘inner part of a house’, *gun’a ‘shabby clothes, rags’, *kordъ ‘short sward’, *toporъ ‘axe’ etc., plus a separately standing group of religious terms and names of gods. However, even if any of these words are indeed borrowings they may not necessarily be ‘iranisms’ in the true sense (i. e. direct borrowings from one of the attested Iranian languages). Read the rest of this entry »
Dear Visitor,
Welcome to my WordPress blog!
See my profile and some selected papers on the following pages.

